Our Data Driven Approach to Fixing Payment Reliability
After a few months of testing, we've improved reliability +600% and can now hit most of our probing targets with 1,000,000 sats 95% of the time. Find out more about how we solved this problem on Lightning.

Since we launched in July, we have struggled with failed payments amongst our users. We must admit, it's a bit of a "tail between our legs" moment to have gone through the technical feats we've accomplished so far and then struggle with something existing wallets and custodians in this space haven't had a problem with in many years. Any lightning wallet should be able to... send lightning payments reliably.
We're building on the Lightning Dev Kit, an excellent toolset for devs to create their own node/wallet. However, it is also a new project compared with other Lightning implementations. Each takes a different approach to routing, and many are experimenting with different concepts and have multiple routing algorithms built in that the user can choose from. Many years of use and research have gone into some of these routing algorithms, but LDK's approach is still new and needs fine-tuning and testing.
After a few months of testing, with the latest release this week, we've improved reliability +600% and can now hit most of our probing targets with 1,000,000 sats 95% of the time.
The Problem
When routing payments on the Lightning Network, many things can go wrong. The best analogy is one that Roy Sheinfeld from Breez published back in 2018. The Lightning Network is a collection of abacuses where the beads can be on either side across any pair of nodes, and typically, users have no idea what side they could be on.

So when there are 15k nodes and 64k pairs of channels between them, it becomes a guessing game of paths to send a payment from one node to another. Luckily, a few modified path-finding algorithms are prevalent, mostly stemming from the idea of the "shortest path."
One problem is many ideas about what "shortest " means for Lightning. Do you define it by hops? Fees? Time? Maximizing lower fees means targeting cheaper nodes that are not well maintained. The more expensive nodes typically price their liquidity as accurately as possible based on experience, demand, and availability.
It's a similar problem with Google Maps, although they have more insights into live traffic data. We typically do not know such things in Lightning without active probing. And unlike some other Lightning Wallets, Mutiny doesn't see our user's channels, payments, or destinations. We're running on very little info to solve this problem.
So, for months, the question for us has been, "How do we improve payment reliability in Mutiny without sacrificing user or network privacy?"
What we've done
Basic Algorithm Tweaks
In the beginning, we tried tweaking some of the LDK routing parameters. There is a wide range of parameters that can be tweaked, but the two we had intuition and advice for were base_penalty_msat and base_penalty_amount_multiplier_msat, which basically apply a penalty for each hop that it has to take. In the case of LDK, it's still a shortest path algorithm, but it considers more than just fees into its weights. It considers fees, hops, the total liquidity of each hop, previous history routing through specific nodes, and a few other parameters.
So, we first tried multiplying the penalty for each hop by 5. This meant we were willing to pay up to 5x the fees to take a more preferred hop in a route since fees and algorithm penalties are weighted together. Since anything can go wrong between each pair of nodes, cutting down on hops should mean cutting down on failure rates. During the Lightning Commerce panel I hosted at Bitcoin 2022, other custodians like Strike and ZBD mentioned that they were seeing success rates drop ~20% even after one hop.
Cutting down on hops should help. I still remember the night before launching, Ben and I were at our hotel till 3am trying to pay the Bitcoin Park storefront and seeing what would work. Unfortunately, we didn't get much success with this attempt. In hindsight, the default penalties were not aggressive enough in the first place. We'll come back to this.
Remote Scorer
When the tweaks didn't do enough for us, we wanted to take the unique approach of shipping a probed network state to each user. We shipped this a few months ago and did notice an improvement, though we couldn't quantify it except for user feedback and our own experiences.
Since LDK has the concept of a probabilistic scoring algorithm that learns from its past payments, we wanted to take advantage of that. The act of probing across the ecosystem is standard. Any custodian that sends out payments on behalf of users needs to be able to provide them quick and fail-less payments in addition to an upfront fee that is manageable. The exact fee is not known until a successful payment (or route) is found. Probing helps custodians get the precise fee before showing the user. Just-in-time probes are standard across the board for payment checks, though different than the revealing act of balance probing, which is another concern.
The unfortunate part for mobile users in a self-custodial wallet is that they do not get the luxury of probing. They're only online to make that payment, so there's no background or continuous probing to learn about the network. On top of that, we want users to refrain from doing their own probing. That doesn't scale. It's one thing for an exchange to probe the network on behalf of thousands of users benefiting, but thousands of users probing the network for themselves wouldn't work. So we probe it continuously for our users and give them the results. We can even provide it for other LDK-based wallets that want to improve their routing. Reach out if that's the case.
Since we don't know anything about our user's payments, we hand-selected about 40 nodes that are common destinations as a baseline. We want to include more and randomly select more edge nodes across the network. First, we need to sort out the algorithm before dealing with so many failed payments trying to reach the outer network since we already have a problem with the inner network.
When our prober found a successful route to a destination, it would mean that all of our users could also take that route. However, it may only work for the first few users, or if enough time passes, that route is no longer available. The prober helped, but it didn't seem like enough successful routes would occur. And even then, we still had users with unexplainable routing failures for consistently reachable destinations. So what next?
More Rapid, Rapid Gossip Sync
To speed up syncing Lightning Network gossip for users, we employ a technique for compressing gossip info called Rapid Gossip Sync (RGS) made by the LDK team. This collects all the gossip and, every 24 hours, ships a minified version that is 4MB or less. I've seen the gossip process take minutes sometimes on other wallets. We want wallet startup to be less than ~5 seconds, though we still need to cut this number down more.
While still dealing with users who had many failed payments, we asked them to send us their logs. We don't do automatic log collections, so the ones that wanted to help emailed or submitted to GitHub. Eventually, we started to see some consistencies that shouldn't have been there:
Onion Error[from 02..: fee_insufficient(0x100c) htlc_msat(0000039387000088)] Node indicated the fee amount does not meet the required levelWe noticed up to 90% of the Lightning failures were due to incorrect fee errors. Our new prober never had a chance to kick in on end-user devices.
The problem we noticed is that many nodes would update their fees throughout the day. In fact, one day, our LSP increased all of their channel fees, which made the wallet useless until the next day's RGS sync. The nodes would reject the payment since the wallet was undercutting the fees. We took this to the LDK team, who released a version allowing this to be configurable. They switched theirs to run at a 3-hour sync. We forked RGS, added remote Postgres + SSL support, and set the default to 1-hour syncing. We also only do full syncs instead of partial due to a few bugs around merging partial syncs, resulting in missing gossip for some users. There are still some bugs we have found recently that result in fee mismatches, but we're sure they can be resolved.
This helped a lot, and when we looked at user-provided logs, we stopped seeing the incorrect fee error. We still had too many user-reported routing failures that we also experienced ourselves, but at least we were eliminating one bug at a time.
Probing Visualizations
Since our data probing was kicking in, failure rates still seemed high. We were still determining if it was due to the connectivity of the Voltage Flow 2.0 LSP. We could explore additional LSPs, but needed to know if we would still have these routing problems elsewhere. This led us to save each probe's result and to throw a few potential LSP partners into the probing list.
Over a few weeks, we've been able to visualize our probed results and could make algorithm changes to compare how they did.
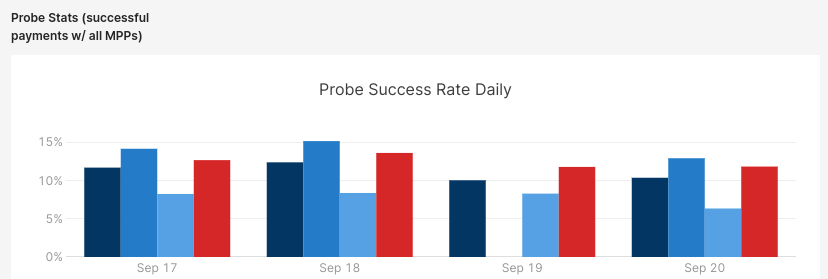
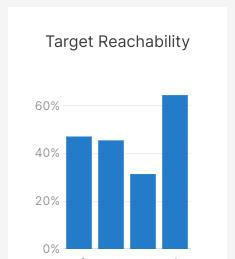
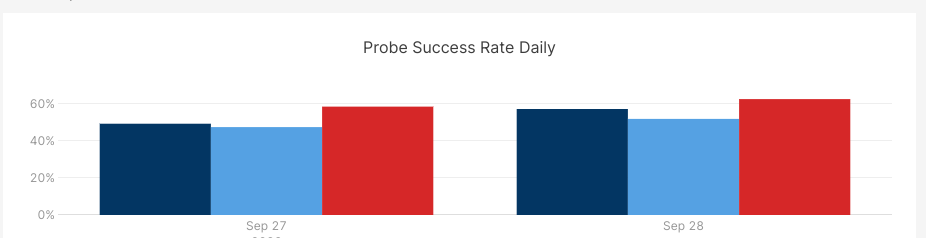
We noticed that with the "LDK defaults 5x hop penalty" approach, we were getting about a 10% - 12% success rate across all our targets and various amounts we tried. We are tracking the latest highest probed amounts and found that if we were targeting 1 million sat probes on each node, we only got 30% - 60% of that on average.
We send thousands of probes daily across multiple LSPs, and even with the probabilistic learning that LDK does, more is needed for consistent payments.We started looking at the hops and multi-part payment paths next.
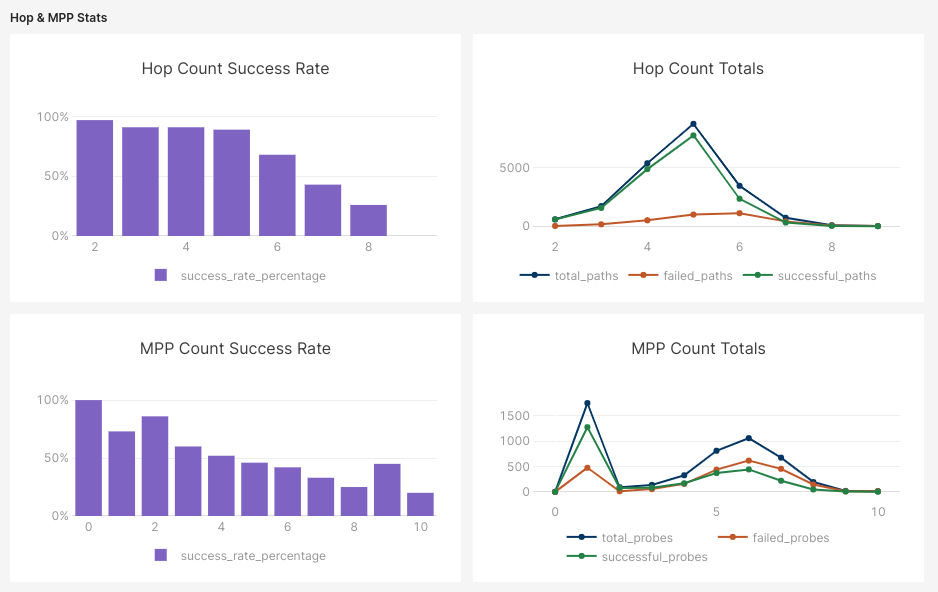
As each hop is taken, there's a significant drop-off. At 6 hops, it was about a 60-70% success rate from our tests, and unfortunately, most payments end up attempting at 6+ hops with that current algorithm.
For Multi-Part Payments, the payment is split with different amounts and hops. For example, if a path with 6 hops has a 50% failure rate and a payment/probe decides to split the payment in two, odds are the payment will fail even if one path succeeds. That's why we can see payment success rates go down as more MPP parts happen.
This led us to be more aggressive about hops and nodes.
Hub Highways
I was thinking more deeply about this while researching Private Information Retrieval by Sergei Tikhomirov. I noticed there was a section about hubs. He compared hubs to highways during routing algorithms:
- drive to the nearest highway entrance;
- drive along the highway;
- exit the highway and drive to your destination.
Makes a lot of sense. Let's see how that can work in practice.
We determine hubs based on the Terminal list of top nodes, though we want to attempt a more deterministic approach in the future with just lightning data defining what a hub is.
Note: Some may be concerned with Lightning Node ranking lists being a centralizing factor for a hub and spoke-like network, but in my opinion, there are still hundreds of nodes that still make the cut, and our prober is still demonstrating 5 hops on average which is pretty good onion routing privacy considering that The Tor Project has converged onto 3 hops being enough. Plus, it gets a better anonymity set through popular endpoints with lots of routing activity. This doesn't avoid alternate routes. It prefers hubs when it knows there's a high likelihood of routing the payment. The reality is that the network is filled with too many unmaintained nodes that are useless for routing through reliably.
We first attempted a lightweight version of this method but saw little success after a few days. When we amplified the parameters and increased the hop penalty, we started seeing some success we could finally point to. This code is what we ended up with:
fn channel_penalty_msat(
&self,
short_channel_id: u64,
source: &NodeId,
target: &NodeId,
usage: ChannelUsage,
score_params: &Self::ScoreParams,
) -> u64 {
// normal penalty from the inner scorer
let mut penalty =
self.inner
.channel_penalty_msat(short_channel_id, source, target, usage, score_params);
let hub_to_hub_min_penalty = (score_params.base_penalty_msat as f64 * 0.5) as u64;
let entering_highway_min_penalty = (score_params.base_penalty_msat as f64 * 0.7) as u64;
if self.is_preferred_hub(source) && self.is_preferred_hub(target) {
// Both the source and target are on the "hub highway"
penalty = penalty.saturating_mul(5).saturating_div(10); // 50% discount
penalty = penalty
.saturating_sub(HUB_BASE_DISCOUNT_PENALTY_MSAT)
.max(hub_to_hub_min_penalty); // Base fee discount
penalty = penalty.max(hub_to_hub_min_penalty);
} else if self.is_preferred_hub(target) {
// Only the target is a preferred hub (entering the "hub highway")
penalty = penalty.saturating_mul(7).saturating_div(10); // 30% discount
penalty = penalty.max(entering_highway_min_penalty);
} else if self.is_preferred_hub(source) {
// Only the source is a preferred hub (leaving the "hub highway")
// No discount here
penalty = penalty.max(score_params.base_penalty_msat);
} else {
// Neither the source nor target is a preferred hub (staying "off the highway")
penalty = penalty.saturating_mul(15).saturating_div(10); // 50% extra penalty
penalty = penalty
.saturating_add(HUB_BASE_DISCOUNT_PENALTY_MSAT)
.max(score_params.base_penalty_msat); // Base fee penalty
penalty = penalty.max(score_params.base_penalty_msat);
}
penalty
}
As far as the algorithm goes, it is pretty simple:
- 50% penalty discounts to hops between two hubs
- 30% discount from entrance nodes to a hub
- no change to exit from hub to non-hub
- 50% increase in penalty for non-hub routing to non-hub.
- We also increased the hop penalties by about 100x instead of 5x.
The fact that we can quickly develop these preferences is a huge testament to the power of LDK. They've also been a lot of help during this process. After tweaking these on mainnet, we've seen some incredible results.
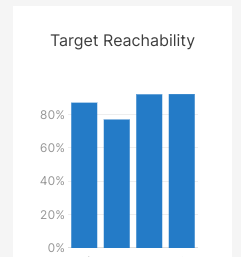
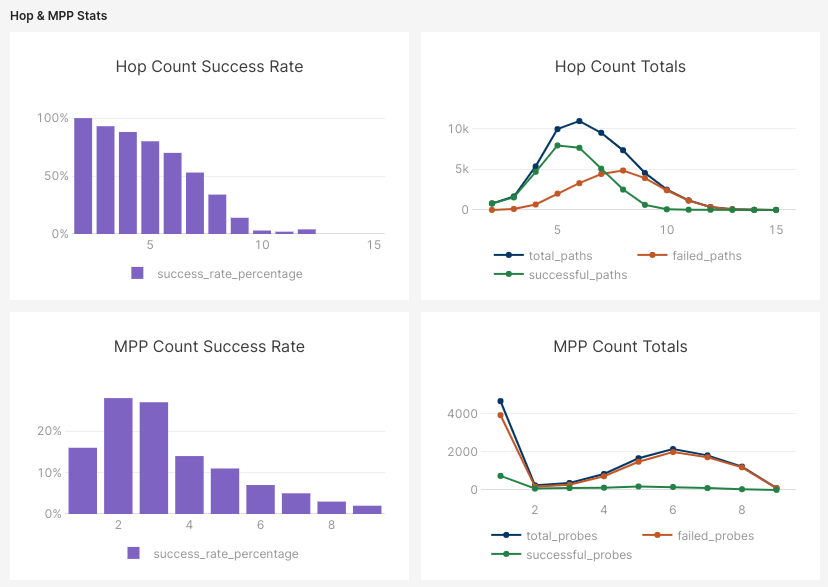
Our max amount reachability skyrocketed to 95% on the Voltage LSP, with up to a 63% success rate now for all probes.
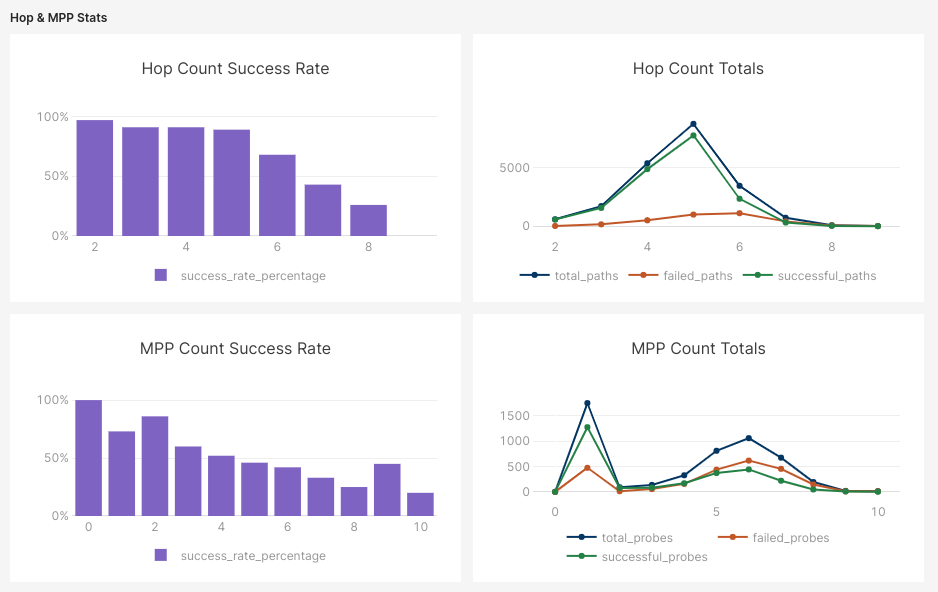
Regarding the hops and paths being taken now, hops have a more gradual decline as they maintain an 89% success rate at 5 hops, with 5 being the most common amount. We now hardly see any paths taken after 6 hops, and the overall MPP success rate is much higher as a result, with most hops succeeding successfully across all of them.
We've only been running this for a few days, but we're excited to go ahead and get it out there since it is such a vast improvement. The great thing is that the fees stayed relatively low. Even for 1 million sat probes, the fee typically remains at 0.2% or lower. Looking back at the fees with the default 5x algo we were running, those were about 50% to 80% lower, but with the cost of the time wasted in failed probes to get to that point. If it goes through, it's only saving about 20 cents on a $250+ payment. And that's a big if.
Conclusion
We now have an even more rapid RGS, a prober that feeds info to each Mutiny user whenever they load the wallet, a probing and LSP visualization platform that lets us compare algorithms and LSPs based on live real-world simulated payments, and a new hub-based algorithm that significantly improves payment reliability.
We're still not done making sure payments are more reliable for users, but we really want to know if these are working better now, so please let us know! We will keep iterating on this hub-preferred algorithm and add more targets to our probe list. We may open-source a portion of this data at some point if it would be helpful for others. Let us know if you have any interesting use cases or want to be considered as one of Mutiny's embedded LSPs.
We're interested in combining probing data with gossip data to create a reinforcement learning AI that can hook into our prober to continue learning from, with the plan to take the trained model and ship it to end users. When trampoline routing comes along, this may be very useful to us from a reliability and privacy standpoint.